Abstract
In this paper, we propose a Self-heuristic Speaker Content Disentanglement (S2CD) model for any_to_any voice conversion without using any external resources, e.g., speaker labels or vectors, linguistic models, and transcriptions. S2CD is built on the disentanglement sequential variational autoencoder (DSVAE), but improves DSVAE structure at the model architecture level from three perspectives. Specifically, we develop different structures for speaker and content encoders based on their underlying static/dynamic property. We further propose a generative graph, modelled by S2CD, so as to make S2CD well mimic the multi-speaker speech generation process. Finally, we propose a self-heuristic way to introduce bias to the prior modelling. Extensive empirical evaluations show the effectiveness of S2CD for any_to_any voice conversion.
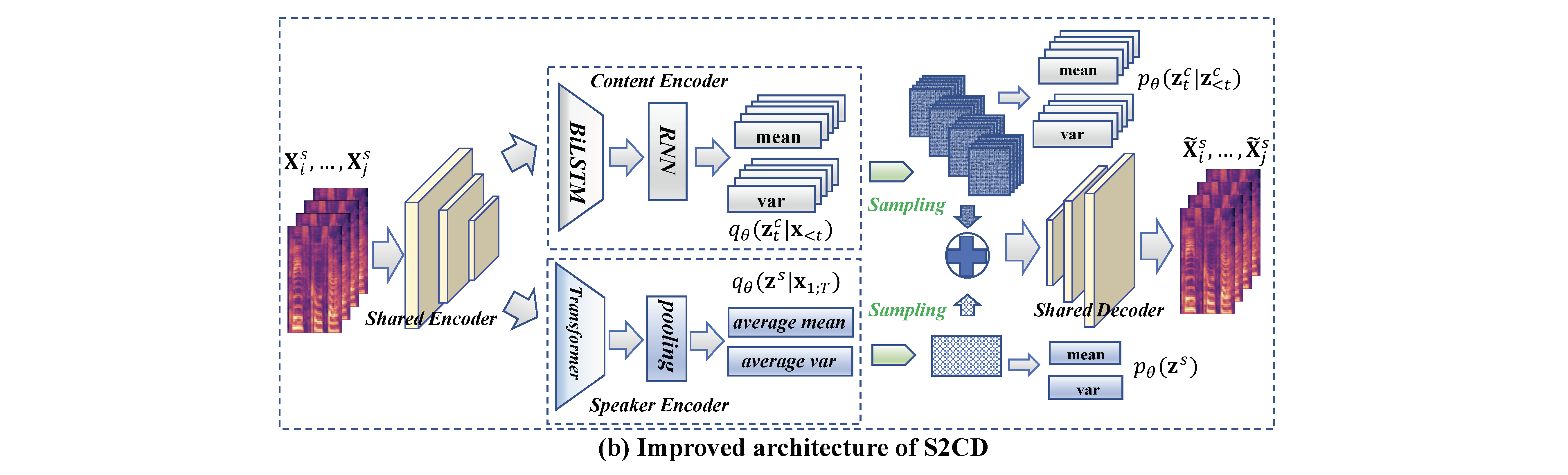
Key Points of S2CD
Compared with DSVAE, S2CD makes the following improvements:
- Different structures for speaker and content encoders
- Positive pair-wise training based on a multi-speaker speech generation graph
- self-heuristic prior modelling
Voice Conversion Demo Samples
Unseen2unseen
Female2Male:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Male2female:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Male2Male:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Female2Female:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Seen2seen
Female2Male:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Male2female:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Male2Male:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |
Female2Female:
| Models | Example 1 | Example 2 |
|---|---|---|
| Source | ||
| Target | ||
| DSVAE | ||
| S2CD_woT&P | ||
| S2CD_woT | ||
| S2CD |